Software Testing Methodologies & Approaches to Fuzzing
This blog post is part of a series and a re-posting of the original article “Fuzzing 101” that I have written for Yarix on YLabs.
Table of Contents
Introduction
In this article, I would like to introduce fuzz testing as part of a vast overview of software testing approaches used to discover bugs and vulnerabilities within applications, protocols, file formats and more.
Application Security
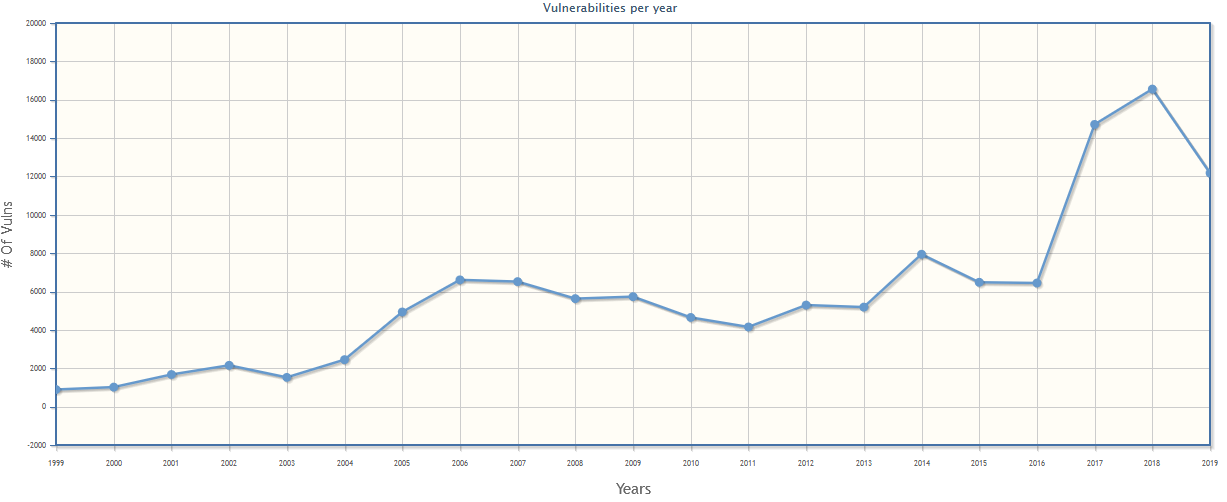
With an ever-increasing number of vulnerabilities discovered during the years, many organizations still spend little budget and effort to produce and ensure code quality and, even when they do extensive testing and assess their code, bugs are unavoidable.
Code review and, in general, finding bugs is complex and require a lot of effort on both skilled humans and technology.
Companies that are not willing to spend time and money into correcting bugs end up paying for it in corrective efforts after the application is released. Worst-case scenario? It can cause a loss of customers and/or revenue.
We all remember 2017 Equifax’s data breach caused by an unpatched Apache Struts framework in one of its databases; Equifax had failed to fix a critical vulnerability months after a patch had been issued which resulted in a $ 575 million settlement with the Federal Trade Commission (FTC).
Usually, the further a bug moves undiscovered into the latest stages of development the higher are the costs for fixing it.
That’s why organizations often employ security testing tools in early development stages to promptly find and fix vulnerabilities and bugs. Nowadays Static Application Security Testing (SAST) tools are widespread among development teams but, huge software vendors and security researchers also started to employ Fuzzing aka Feedback Application Security Testing (FAST) methodology.
Software Testing Approaches
Static Application Security Testing (SAST)
SAST is probably the oldest of the methods covered in this article. SAST uses a fully white-box approach where the source code is scanned without being executed. The entire codebase is searched for suspect patterns and dangerous functions usage, which could indicate potential vulnerabilities.
Pro
- Since SAST employ a white-box approach, it offers the maximum code coverage, the entire code base is scanned.
- Since SAST does not need executable code, it can be used at any stage of the Software Development Lifecycle (SDLC).
Cons
- SAST biggest strength (white-box approach) is also its biggest disadvantage as it requires access to the source code.
- As SAST does not execute the code, it cannot discover runtime issues. It is also not a good choice where user inputs or external libraries are required.
- SAST produces large numbers of false positives/negatives. Large and complex projects will easily generate thousands of warnings to be manually reviewed.
Software Composition Analysis (SCA)
SCA is similar to SAST, however, its main goal is to identify all open-source components, libraries and dependencies in a codebase and to map that inventory to a list of current known vulnerabilities.
Dynamic Application Security Testing (DAST)
In DAST the source code is compiled, executed and then scanned at runtime in search of security vulnerabilities. Randomized and predetermined inputs are passed to the application under the test, if the behaviour of the application differs from the predefined correct responses or the program crashes, a warning is logged, meaning a bug in the application has been discovered.
Pro
- Main DAST advantage is that there are (almost) no false positives since the application’s behaviour is analysed.
- DAST is used to discover runtime issues and it is the right choice when user interaction is required.
- DAST does not need the source code of the application under testing (black-box approach).
Cons
- DAST requires a working application to be tested.
- Since there is nothing to guide the generation of random inputs, DAST does not provide good code coverage and can be very inefficient
- It is hard to map the discovered errors back into the source code to fix the problems.
Interactive Application Security Testing (IAST)
IAST is a hybrid version of the two, combining the benefits of SAST and DAST.
The dynamic approach (DAST) is commonly used to test and filter out warnings produced by SAST to increase the accuracy of the application security testing. Instrumentation allows DAST-like confirmation of exploit success, improve its performance and SAST-like code coverage of the application source code.
Fuzzing/Feedback-based Application Security Testing (FAST)
Pure DAST solutions and black-box testing, in general, have low code-coverage as they rely on random, pattern-based or brute-force approaches to generate input and test cases.
Bleeding edge fuzzing employ Feedback-Based (coverage-guided) fuzzing techniques instrumenting the software being tested to identify vulnerabilities and bugs; it can be complemented by Reverse Engineering (if the application is closed source). During the fuzzing process, random inputs are “sent” to the software under test, while its behaviour is monitored, until a crash is triggered. The input which caused the crash is then recorded and analysed to derive information that can be used to exploit (or fix) the bug in the application.
The fuzzer gets feedback about the code covered, when executing each input, allowing the mutation engine to measure the input quality. At the core of the mutation engine are genetic algorithms used to optimize code coverage as a fitness function. Generated inputs resulting in new code paths (or basic blocks or edges; depending on the fuzzing coverage metrics used), maximizing code coverage and thus increase the probability of triggering bugs, are prioritized and are used during the next batch of mutations.
Google, for example, already use modern fuzzing technologies to automatically test their code for vulnerabilities. As of January 2021, OSS-Fuzz has discovered over 25000 bugs in 375 open-source projects.
Pros
- FAST produces almost no false positives. If the fuzzer finds something, it is usually a confirmed problem.
- FAST automatically maximizes the code coverage and is highly automated. Once a fuzzer is up and running, it can search for bugs without further manual interaction.
- Depending on the fuzzing type, source code might not be needed.
Cons
- FAST requires a working application to be tested.
- FAST needs special expertise (e.g., harness writing) and testing infrastructure.
A bit of history
According to Wikipedia, the term “fuzz” originates in 1988 as part of a class project at the University of Wisconsin. The project was designed to test the reliability of UNIX command-line programs by executing a large number of random inputs in quick succession until they crashed. Prof. Barton Miller’s team was able to crash 25-33% of the utilities that they tested.
Requirements
- Documentation: documentation about the target to evaluate.
- Target: the target to evaluate.
- Harness: used to generate the test cases.
- Monitoring & Crash Analysis: depending on the chosen fuzzing technique a method to monitor the target is required; a method to identify when a crash is reached on the target is also required.
- Time & Patience: building harness, test cases minimization and fuzzing runs are time-consuming tasks.
Types of Fuzzing Engines
Dumb/Black Box
These fuzzing engines generate input completely random, either from nothing or through mutation. Input generation does not follow any structure or grammar and does not consider what input format is expected by the target software. The engine does not receive any feedback about the code coverage.
A dumb fuzzer is easy and inexpensive to set up but is also the most inefficient.
Smart
These engines have the ability to conform input to some kind of structure or grammar and produce inputs that are based on valid input formats. This ensures that inputs provided to targets match certain patterns.
A smart fuzzer recognizes desired input format and produces inputs matching that format. This type of fuzzing requires detailed knowledge about input format and thus takes longer to set up.
Fuzzing Techniques
Static Test Case
One of the possible techniques for fuzzing a target will be to build multiple static test cases of malformed data. During the target’s analysis phase, interesting, unusual or error-triggering conditions are noted and then isolated into single test cases. Lots of up-front development time is required and the scope of the test is limited by the number of test cases built but among its advantages, there is the simplicity of reproducing the test across multiple targets and the ease of test case sharing.
Mutation-Based
These fuzzers start with a valid frame or data set and alter original valid input samples, by introducing small changes (e.g., mutates one byte/short/long at a time), to create new inputs. With each mutation, the original input will slowly begin to deviate increasingly from the original.
Generation-based
These fuzzers can generate new inputs from scratch. In contrast to mutation-based fuzzers, no original valid input is needed to start producing new inputs. However, generated inputs must follow a certain data model or structure in order to reach the corresponding code coverage.
Feedback-based/Coverage-based
These fuzzers leverages code instrumentation to gain insight into how inputs affect the target application. Code coverage information is used when generating new inputs, allowing coverage-based fuzzers to increase its code coverage over time and test more paths in programs by monitoring which inputs reach which parts of a target.
Upcoming Article
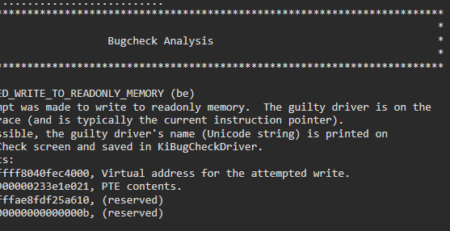
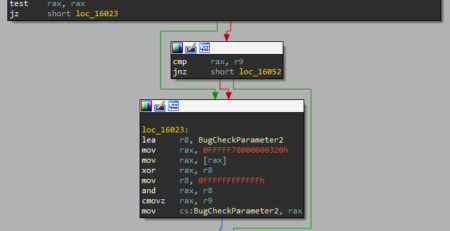
In the next blog post, we will dive into File Format Fuzzing and I’ll disclose the process that led me to discover 5 different vulnerabilities (out of ~104 unique crashes) in FastStone Image Viewer v.<=7.5, achieving Arbitrary Code Execution:
- CVE-2021-26233 – User mode write Access Violation
- CVE-2021-26234 – User mode write Access Violation
- CVE-2021-26235 – User mode write Access Violation
- CVE-2021-26236 – Stack-based Buffer Overflow
- CVE-2021-26237 – User mode write Access Violation